在实际使用中,需要编写java程序来执行hadoop中的运算任务。为了方便调试代码,使用IDEA来编辑,本机的hadoop环境是在docker中运行的,如果可以用IDEA连接hadoop环境,直接显示代码在hadoop集群中的运行结果,就会比较方便。
1. IDEA构建本地开发调试环境
1.1 创建项目
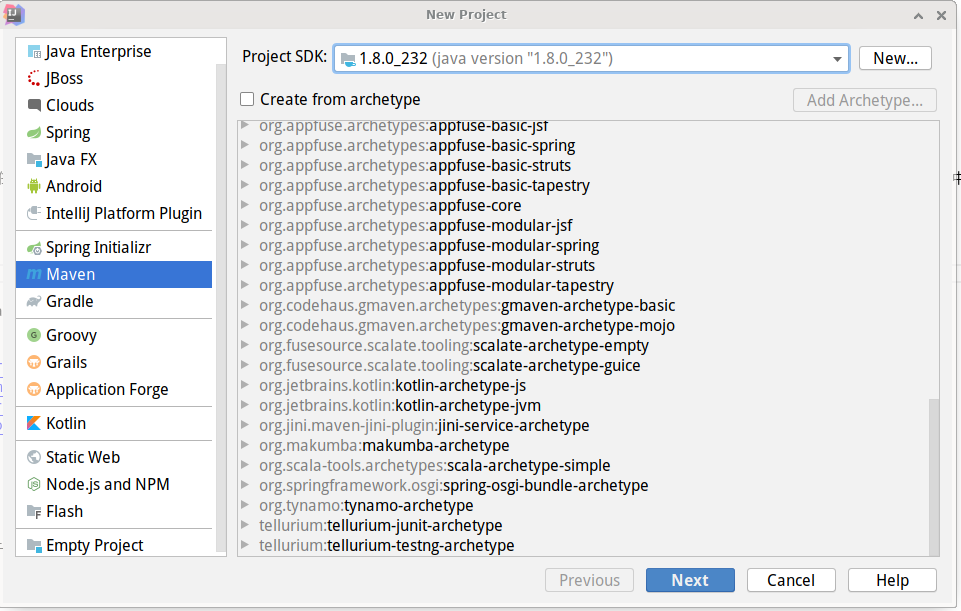
首先创建maven项目,命名为wordcount,注意JDK版本(其实maven也不是很有必要,下载hadoop二进制安装包,导入里面的包也可以)
1.2 添加maven镜像
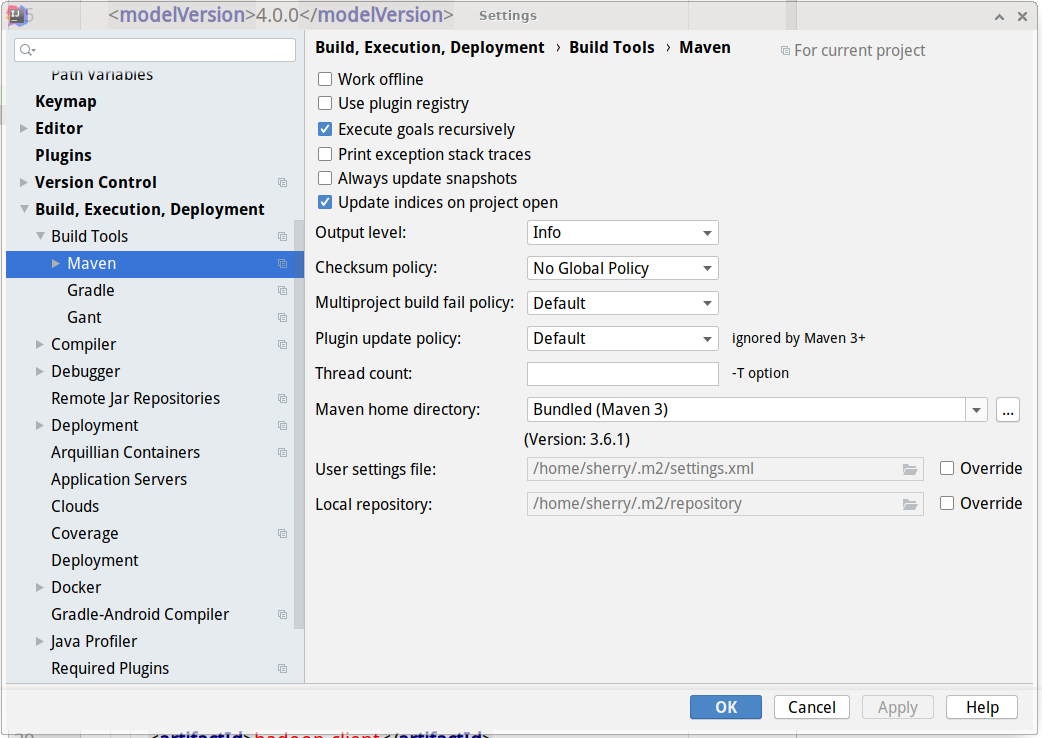
通常配置文件为~/.m2/settings.xml,也可以在idea中查看maven配置文件的位置,没有的话就新建一个
1
2
3
4
5
6
7
8
9
10
11
12
13
<settings xmlns= "http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi= "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation= "http://maven.apache.org/SETTINGS/1.0.0
https://maven.apache.org/xsd/settings-1.0.0.xsd" >
<mirrors>
<mirror>
<id> aliyunmaven</id>
<mirrorOf> *</mirrorOf>
<name> 阿里云公共仓库</name>
<url> https://maven.aliyun.com/repository/public</url>
</mirror>
</mirrors>
</settings>
1.3 添加hadoop依赖
在配置中添加部分hadoop依赖,然后根据idea的提示import changes
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns= "http://maven.apache.org/POM/4.0.0"
xmlns:xsi= "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation= "http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" >
<modelVersion> 4.0.0</modelVersion>
<groupId> org.example</groupId>
<artifactId> wordcount</artifactId>
<version> 1.0-SNAPSHOT</version>
<properties>
<hadoop.version> 2.10.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId> org.apache.hadoop</groupId>
<artifactId> hadoop-common</artifactId>
<version> ${hadoop.version}</version>
</dependency>
<dependency>
<groupId> org.apache.hadoop</groupId>
<artifactId> hadoop-client</artifactId>
<version> ${hadoop.version}</version>
</dependency>
<dependency>
<groupId> org.apache.hadoop</groupId>
<artifactId> hadoop-hdfs</artifactId>
<version> ${hadoop.version}</version>
</dependency>
</dependencies>
</project>
1.4 创建主程序
在src->main->java下新建WordCount类,使用官网上教程 的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
import java.io.IOException ;
import java.util.StringTokenizer ;
import org.apache.hadoop.conf.Configuration ;
import org.apache.hadoop.fs.Path ;
import org.apache.hadoop.io.IntWritable ;
import org.apache.hadoop.io.Text ;
import org.apache.hadoop.mapreduce.Job ;
import org.apache.hadoop.mapreduce.Mapper ;
import org.apache.hadoop.mapreduce.Reducer ;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat ;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat ;
public class WordCount {
public static class TokenizerMapper
extends Mapper < Object , Text , Text , IntWritable >{
private final static IntWritable one = new IntWritable ( 1 );
private Text word = new Text ();
public void map ( Object key , Text value , Context context
) throws IOException , InterruptedException {
StringTokenizer itr = new StringTokenizer ( value . toString ());
while ( itr . hasMoreTokens ()) {
word . set ( itr . nextToken ());
context . write ( word , one );
}
}
}
public static class IntSumReducer
extends Reducer < Text , IntWritable , Text , IntWritable > {
private IntWritable result = new IntWritable ();
public void reduce ( Text key , Iterable < IntWritable > values ,
Context context
) throws IOException , InterruptedException {
int sum = 0 ;
for ( IntWritable val : values ) {
sum += val . get ();
}
result . set ( sum );
context . write ( key , result );
}
}
public static void main ( String [] args ) throws Exception {
Configuration conf = new Configuration ();
Job job = Job . getInstance ( conf , "word count" );
job . setJarByClass ( WordCount . class );
job . setMapperClass ( TokenizerMapper . class );
job . setCombinerClass ( IntSumReducer . class );
job . setReducerClass ( IntSumReducer . class );
job . setOutputKeyClass ( Text . class );
job . setOutputValueClass ( IntWritable . class );
FileInputFormat . addInputPath ( job , new Path ( args [ 0 ]));
FileOutputFormat . setOutputPath ( job , new Path ( args [ 1 ]));
System . exit ( job . waitForCompletion ( true ) ? 0 : 1 );
}
}
在项目目录下新建input文件夹,放入需要统计词频的文件ja.txt
1.6 添加log4j配置
运行WordCount时出现了提示如下:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
在项目目录下的src->main->resources中新建log4j.properties文件,填入如下内容
log4j.rootLogger = info,stdout
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
### 输出DEBUG 级别以上的日志文件设置 ###
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = vincent_player_debug.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
### 输出ERROR 级别以上的日志文件设置 ###
log4j.appender.E = org.apache.log4j.DailyRollingFileAppender
log4j.appender.E.File = vincent_player_error.log
log4j.appender.E.Append = true
log4j.appender.E.Threshold = ERROR
log4j.appender.E.layout = org.apache.log4j.PatternLayout
log4j.appender.E.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
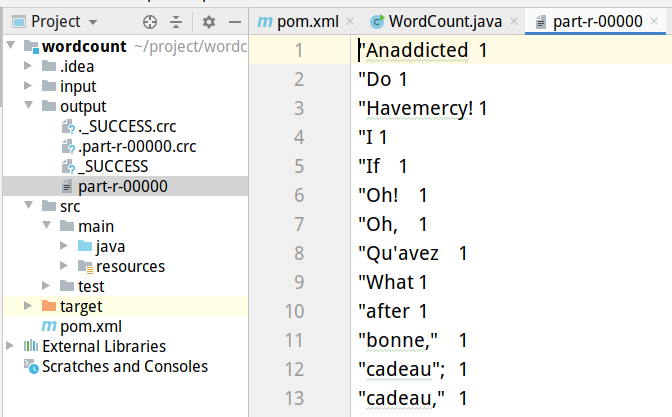
1.7 本地运行结果
运行后即可在当前目录下看到output文件夹,其中的part-r-00000即为分词文件
2. IDEA连接hadoop集群
为了实现集群的map reduce运算,将程序的输入输出连接到hadoop集群的namenode。
2.1 启动hadoop集群
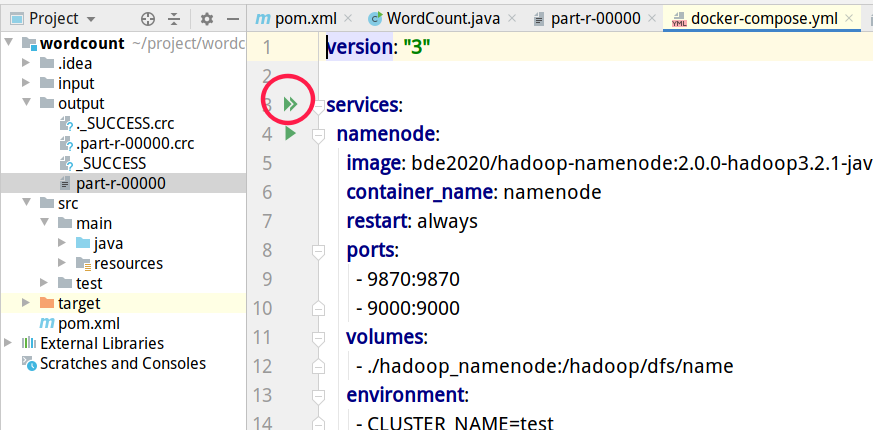
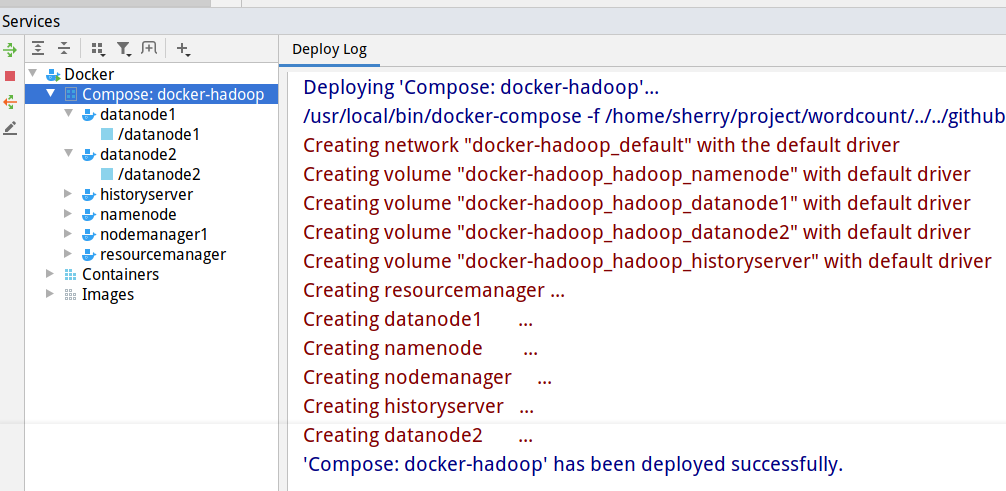
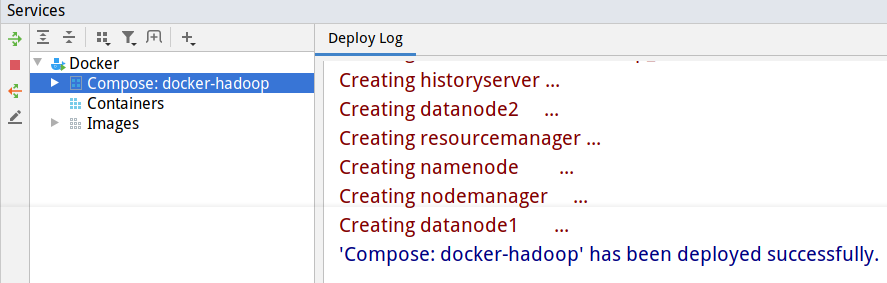
这一步骤可以在终端进行,也可以在IDEA或者VS code中进行,IDEA的好处是可以看到每个container的log,VS code则可以进入container中进行操作,也很方便。docker-compose.yml文件,按照提示点击绿色箭头运行即可
2.2 创建主程序
新建WordCount2类,代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
import java.io.BufferedReader ;
import java.io.FileReader ;
import java.io.IOException ;
import java.net.URI ;
import java.util.ArrayList ;
import java.util.HashSet ;
import java.util.List ;
import java.util.Set ;
import java.util.StringTokenizer ;
import org.apache.hadoop.conf.Configuration ;
import org.apache.hadoop.fs.Path ;
import org.apache.hadoop.io.IntWritable ;
import org.apache.hadoop.io.Text ;
import org.apache.hadoop.mapreduce.Job ;
import org.apache.hadoop.mapreduce.Mapper ;
import org.apache.hadoop.mapreduce.Reducer ;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat ;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat ;
import org.apache.hadoop.mapreduce.Counter ;
import org.apache.hadoop.util.GenericOptionsParser ;
import org.apache.hadoop.util.StringUtils ;
public class WordCount2 {
public static class TokenizerMapper
extends Mapper < Object , Text , Text , IntWritable >{
static enum CountersEnum { INPUT_WORDS }
private final static IntWritable one = new IntWritable ( 1 );
private Text word = new Text ();
private boolean caseSensitive ;
private Set < String > patternsToSkip = new HashSet < String >();
private Configuration conf ;
private BufferedReader fis ;
@Override
public void setup ( Context context ) throws IOException ,
InterruptedException {
conf = context . getConfiguration ();
caseSensitive = conf . getBoolean ( "wordcount.case.sensitive" , true );
if ( conf . getBoolean ( "wordcount.skip.patterns" , false )) {
URI [] patternsURIs = Job . getInstance ( conf ). getCacheFiles ();
for ( URI patternsURI : patternsURIs ) {
Path patternsPath = new Path ( patternsURI . getPath ());
String patternsFileName = patternsPath . getName (). toString ();
parseSkipFile ( patternsFileName );
}
}
}
private void parseSkipFile ( String fileName ) {
try {
fis = new BufferedReader ( new FileReader ( fileName ));
String pattern = null ;
while (( pattern = fis . readLine ()) != null ) {
patternsToSkip . add ( pattern );
}
} catch ( IOException ioe ) {
System . err . println ( "Caught exception while parsing the cached file '"
+ StringUtils . stringifyException ( ioe ));
}
}
@Override
public void map ( Object key , Text value , Context context
) throws IOException , InterruptedException {
String line = ( caseSensitive ) ?
value . toString () : value . toString (). toLowerCase ();
for ( String pattern : patternsToSkip ) {
line = line . replaceAll ( pattern , "" );
}
StringTokenizer itr = new StringTokenizer ( line );
while ( itr . hasMoreTokens ()) {
word . set ( itr . nextToken ());
context . write ( word , one );
Counter counter = context . getCounter ( CountersEnum . class . getName (),
CountersEnum . INPUT_WORDS . toString ());
counter . increment ( 1 );
}
}
}
public static class IntSumReducer
extends Reducer < Text , IntWritable , Text , IntWritable > {
private IntWritable result = new IntWritable ();
public void reduce ( Text key , Iterable < IntWritable > values ,
Context context
) throws IOException , InterruptedException {
int sum = 0 ;
for ( IntWritable val : values ) {
sum += val . get ();
}
result . set ( sum );
context . write ( key , result );
}
}
public static void main ( String [] args ) throws Exception {
Configuration conf = new Configuration ();
GenericOptionsParser optionParser = new GenericOptionsParser ( conf , args );
String [] remainingArgs = optionParser . getRemainingArgs ();
if (( remainingArgs . length != 2 ) && ( remainingArgs . length != 4 )) {
System . err . println ( "Usage: wordcount <in> <out> [-skip skipPatternFile]" );
System . exit ( 2 );
}
Job job = Job . getInstance ( conf , "word count" );
job . setJarByClass ( WordCount2 . class );
job . setMapperClass ( TokenizerMapper . class );
job . setCombinerClass ( IntSumReducer . class );
job . setReducerClass ( IntSumReducer . class );
job . setOutputKeyClass ( Text . class );
job . setOutputValueClass ( IntWritable . class );
List < String > otherArgs = new ArrayList < String >();
for ( int i = 0 ; i < remainingArgs . length ; ++ i ) {
if ( "-skip" . equals ( remainingArgs [ i ])) {
job . addCacheFile ( new Path ( remainingArgs [++ i ]). toUri ());
job . getConfiguration (). setBoolean ( "wordcount.skip.patterns" , true );
} else {
otherArgs . add ( remainingArgs [ i ]);
}
}
FileInputFormat . addInputPath ( job , new Path ( otherArgs . get ( 0 )));
FileOutputFormat . setOutputPath ( job , new Path ( otherArgs . get ( 1 )));
System . exit ( job . waitForCompletion ( true ) ? 0 : 1 );
}
}
(本地运行)拷贝本地的ja.txt文件到namenode节点中
1
docker cp ja.txt <namenode-container-id>:ja.txt
(namenode节点中运行)进入namenode节点,拷贝ja.txt文件到namenode节点的input文件夹中
1
2
hadoop fs -mkdir -p input
hadoop fs -put ja.txt input/
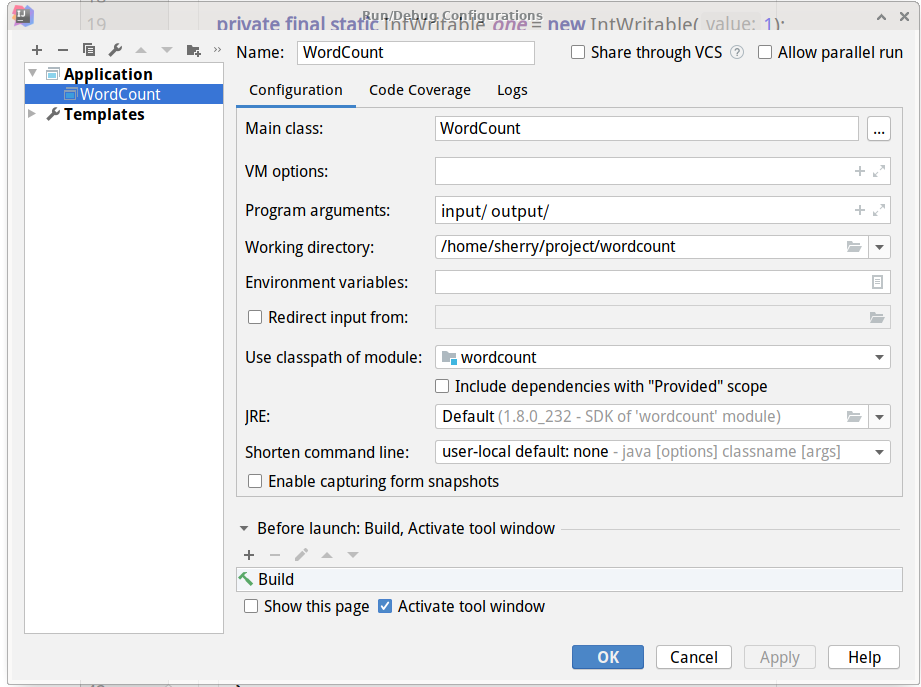
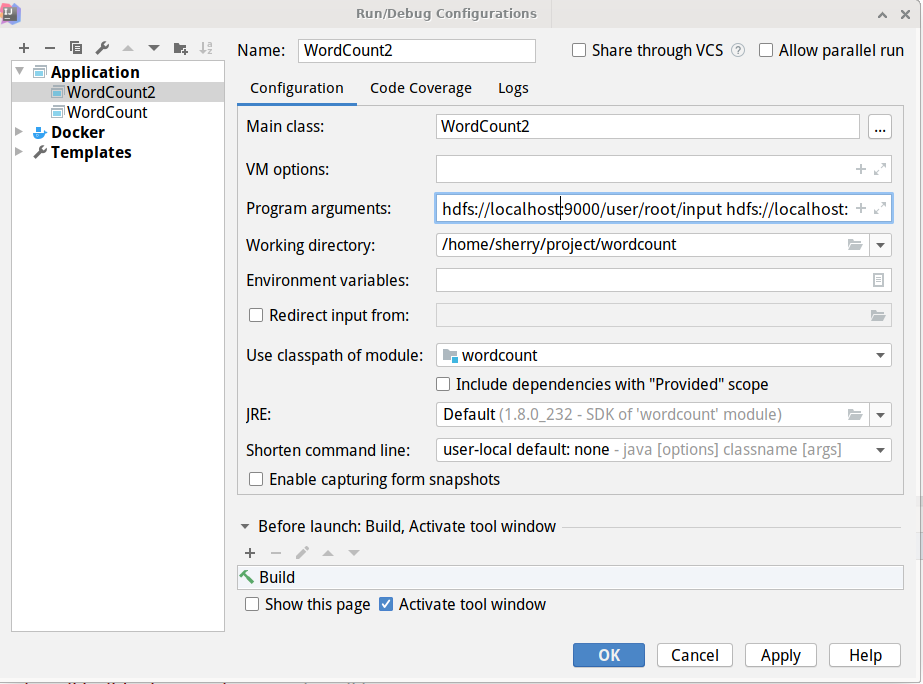
2.3 添加运行配置
在Run中新建名为WordCount2的配置,设置一下运行的参数为hdfs://localhost:9000/user/root/input hdfs://localhost:9000/user/root/output,即使用hadoop集群中的的文件作为输入输出
2.4 运行
(在namenode节点中运行)在namenode节点中可以查看output文件夹
1
hdfs dfs -cat output/part-r-00000
3.打包jar文件
在本地环境中调试好程序后最好打包成jar文件,再部署到hadoop集群中运行会比较方便。
3.1 第一种:maven打包
修改一下之前的pom.xml文件,在project项中添加build项,即可进行打包,但是打包会将所有依赖都包含,因此得到的jar文件比较巨大,有50多MB。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
<build>
<plugins>
<plugin>
<artifactId> maven-assembly-plugin</artifactId>
<configuration>
<appendAssemblyId> false</appendAssemblyId>
<descriptorRefs>
<descriptorRef> jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!-- 此处指定main方法入口的class -->
<mainClass> WordCount2</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id> make-assembly</id>
<phase> package</phase>
<goals>
<goal> assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
3.2 第二种:本地hadoop打包
根据官网教程进行打包
在官网上下载hadoop 2.10.0安装包
1
2
3
4
5
6
# 设置环境
export JAVA_HOME = /usr/lib/jvm/default/
export HADOOP_CLASSPATH = ${ JAVA_HOME } /lib/tools.jar
# 一大串路径为hadoop可执行文件的位置
/home/sherry/software/hadoop-2.10.0/bin/hadoop com.sun.tools.javac.Main WordCount2.java
jar cf wc2.jar WordCount2*.class
得到jar包,复制到namenode节点中
1
docker cp wc2.jar e5f1e244bed3:wc2.jar
(在namenode节点中运行)
1
2
3
4
# 删除上一次运行的output
hadoop fs -rm -r output
# 运行jar包
hadoop jar wc2.jar WordCount2 input output
3.3 debug
运行jar包出现错误,发现datanode容器运行出错,查看运行记录
发现
Failed to add storage directory [DISK]file:/hadoop/dfs/data
java.io.IOException: Incompatible clusterIDs in /hadoop/dfs/data: namenode clusterID = CID-275fc19c-32c5-4065-a768-a8f6ff1498be; datanode clusterID = CID-9c2c037b-6899-4bfe-af1d-34e305d5b181
可能是因为我之前格式化了一次namenode,datanode的数据没有同步,删除/var/lib/docker/volumes/中的所有文件夹再重新启动即可
4.总结
我觉得在namenode容器中进行debug也不是很有必要,可以先在本地运行调试,调试完成后打包jar包复制到namenode节点上,再在hadoop集群上运行计算任务,因此idea的功能就足够了。
参考
https://www.jetbrains.com/help/idea/docker.html https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html https://www.jetbrains.com/help/idea/running-a-java-app-in-a-container.html https://www.polarxiong.com/archives/Hadoop-Intellij%E7%BB%93%E5%90%88Maven%E6%9C%AC%E5%9C%B0%E8%BF%90%E8%A1%8C%E5%92%8C%E8%B0%83%E8%AF%95MapReduce%E7%A8%8B%E5%BA%8F-%E6%97%A0%E9%9C%80%E6%90%AD%E8%BD%BDHadoop%E5%92%8CHDFS%E7%8E%AF%E5%A2%83.html https://blog.jetbrains.com/cn/2019/07/intellij-idea-docker/ https://blog.csdn.net/qq_24342739/article/details/89429786 https://code.visualstudio.com/docs/remote/containers