使用docker在单机上搭建hadoop集群
这个学期正好选了hadoop的课程,也是第一次接触分布式运算的概念,感觉真是特别新鲜。由于条件限制,没有那么多机器可以用来搭建集群,因此只能在单机上进行,为了模拟多个节点,可以使用docker.本次的目标是搭建一个namenode,两个datanode.
1.相关软件的安装
首先安装docker,docker-compose以及docker machine
1.1 manjora
manjora下安装docker
|
|
安装docker-compose比较麻烦,这一步网速比较慢
|
|
也可以去 https://github.com/docker/compose/releases/ 下载对应的二进制文件,复制到/usr/local/bin/下,然后添加可执行权限
|
|
1.2 macos
mac不需要额外安装docker-compose,直接下载docker desktop即可
https://docs.docker.com/docker-for-mac/install/
2.克隆仓库
2.1 github仓库
|
|
2.2 修改配置
修改了一下里面的docker-compose.yml文件(其实就是加了一个datanode节点),注意要把原来目录下的datanode文件夹复制一下,并改名两个文件夹为datanode1 , datanode2
version: "3"
services:
namenode:
image: bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8
container_name: namenode
restart: always
ports:
- 9870:9870
- 9000:9000
volumes:
- hadoop_namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
datanode1:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode1
restart: always
volumes:
- hadoop_datanode1:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
datanode2:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode2
restart: always
volumes:
- hadoop_datanode2:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
resourcemanager:
image: bde2020/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8
container_name: resourcemanager
restart: always
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864"
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8
container_name: nodemanager
restart: always
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:2.0.0-hadoop3.2.1-java8
container_name: historyserver
restart: always
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
volumes:
- hadoop_historyserver:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
volumes:
hadoop_namenode:
hadoop_datanode1:
hadoop_datanode2:
hadoop_historyserver:
3.运行
3.1 拉取并运行镜像
首先启动docker
|
|
在下载的github仓库目录下运行
|
|
拉取镜像的时候遇到了错误
ERROR: Get https://registry-1.docker.io/v2/: dial tcp: lookup registry-1.docker.io: no such host
参考segmentfault以及 https://docker_practice.gitee.io/install/mirror.html 的解决办法,设置一下镜像加速,就可以了
运行完成后是这样样子的
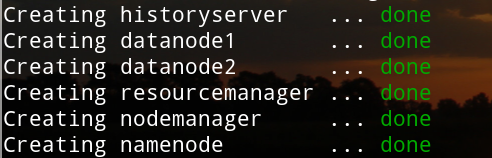
3.2 查看集群信息
让我们查看一下这个hadoop集群正在运行的容器
|
|

也可以访问http://localhost:9870/查看集群的信息
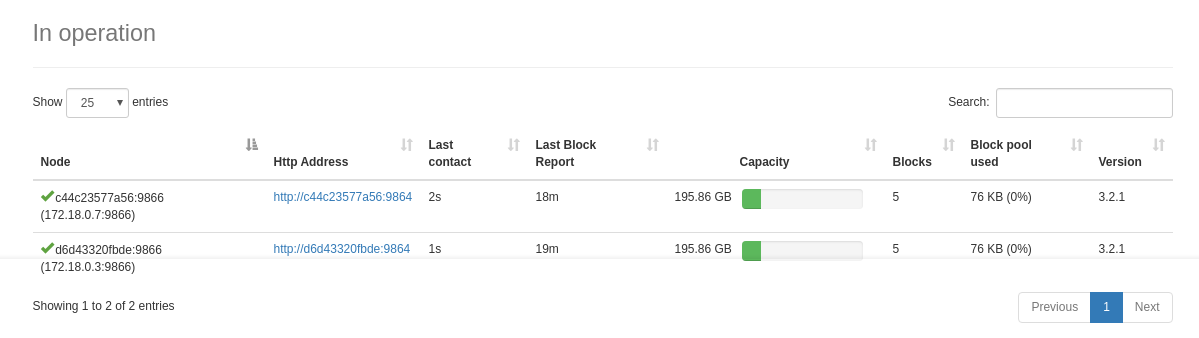
这是datanode的信息
4.运行hadoop
4.1 在namenode中查看datanode信息
首先进入namenode
|
|
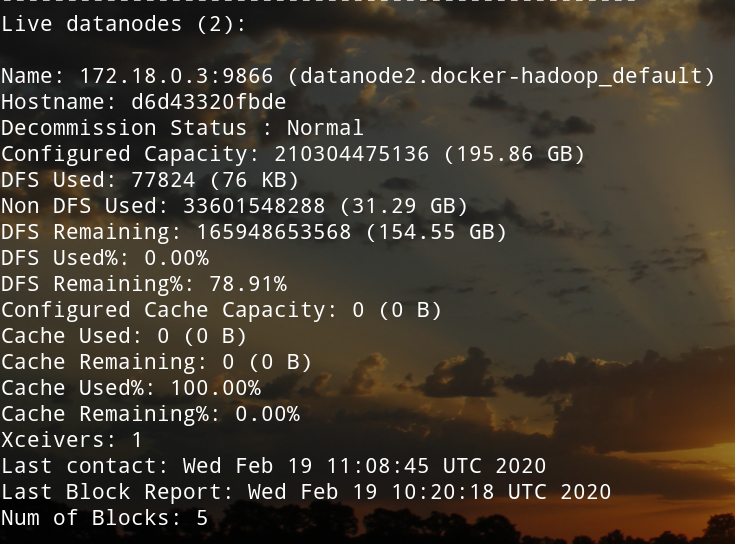
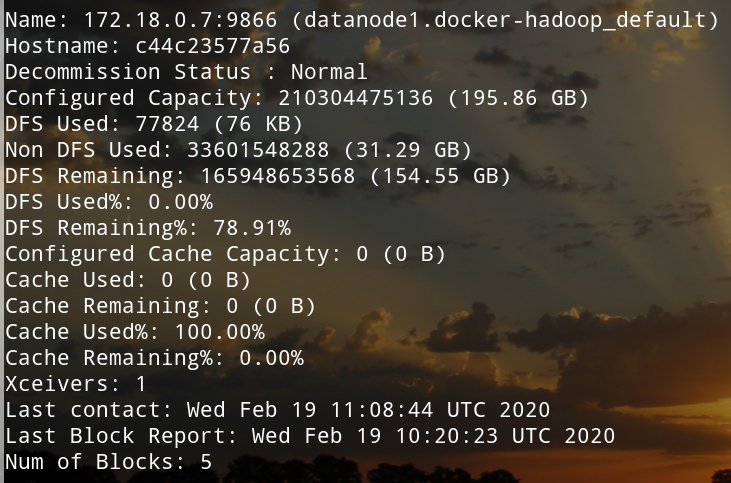
(namenode中)查看datanode状态
hadoop dfsadmin -report
显示出node1和node2的状态信息
4.2 创建文件
(namenode中)同样的先进入namenode再运行如下命令创建文件
|
|
(namenode中)以HDFS格式创建文件夹
|
|
(namenode中)将文件放入datanode
hdfs dfs -put ./input/* input

4.3 本地文件拷贝到namenode中
(在本地)下载以下链接中的jar文件到本地:
(在本地)查看namenode的容器ID
|
|
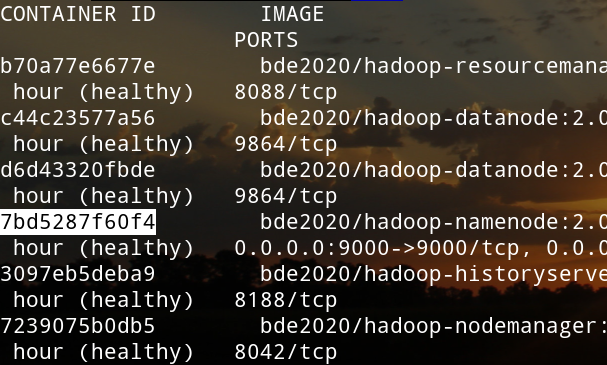
将本地的文件复制到namenode中,替换<namenode-container-id>为刚刚查看的容器ID(在刚刚下载的jar文件的目录下运行)
|
|
(在namenode中)运行jar文件
|
|
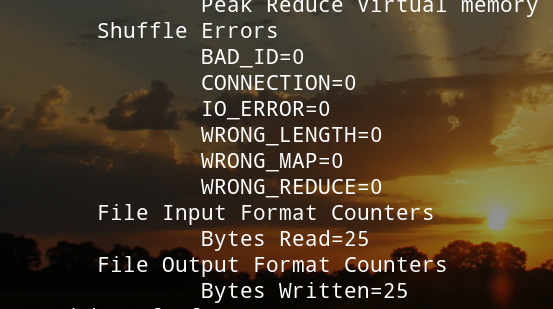
(在namenode中)查看运行结果
|
|

为了下一次进行操作,需要删除output
|
|
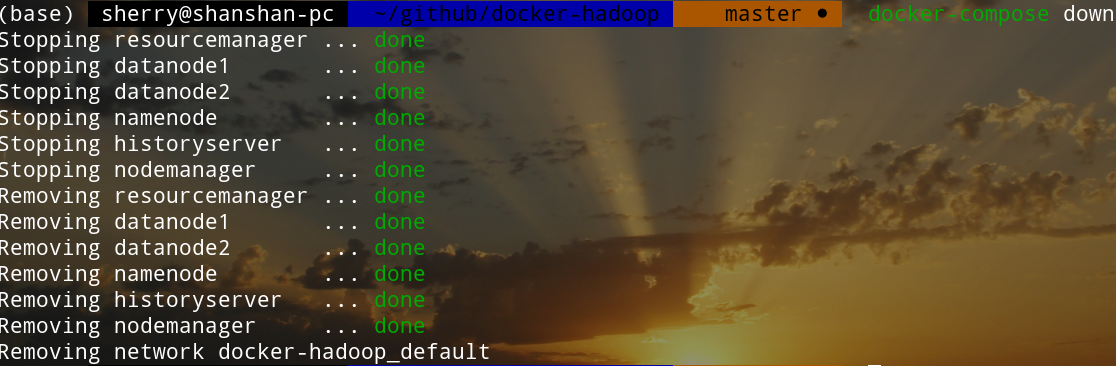
5.关闭集群
先执行exit命令退出namenode节点,然后在之前下载的那个github仓库目录下执行
|
|