[Python爬虫系列]2— 信息采集自动发微博
几个月之前就有做这个项目的想法,自动采集数据并推送。折腾和调试了很久终于有了下面这个半成品,之所以说是半成品是因为这个程序在没有图形界面的服务器还是运行不了(就是新浪微博的验证过不了),而且主要适用于等级较高的微博帐号。
数据采集其实也不难,主要难点是微博的模拟登录(使用selenium以及chrome),所以本文章主要介绍这一部分。
2019/3/13更新
完善了另一个版本的自动发微博项目代码,代码位于 : https://github.com/webscrapingproject/weiboRobot-V2
此项目不基于selenium,通过requests构造请求来登录微博以及发图文微博,需要自动打码平台帐号(超级鹰)以及一个新浪微博图床api key,具体用法请见github上的readme.md
该项目适合在服务器上部署。
## 1.微博基本信息{#weibo-info} 微博的网站主要有三个版本:
- weibo.com 网页版(PC站)
- m.weibo.cn 触屏版(m站)
- weibo.cn 手机版(wap站)
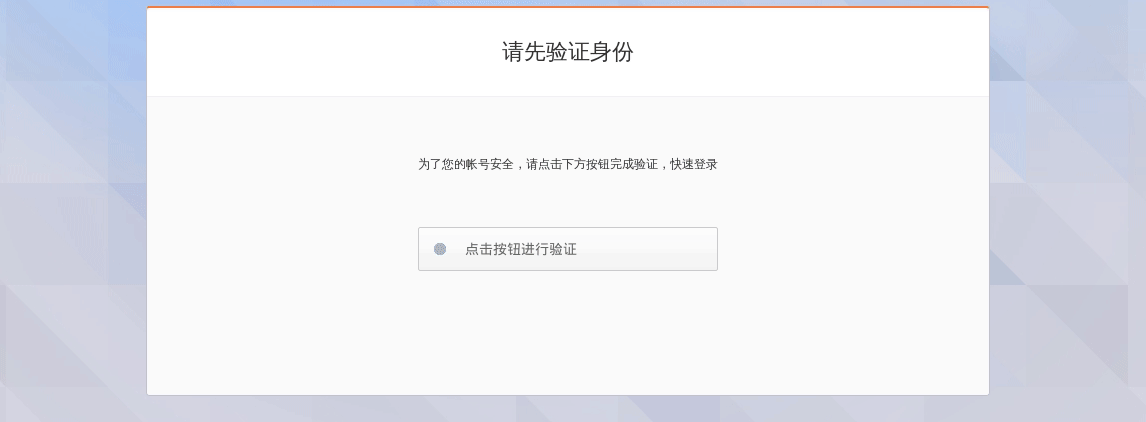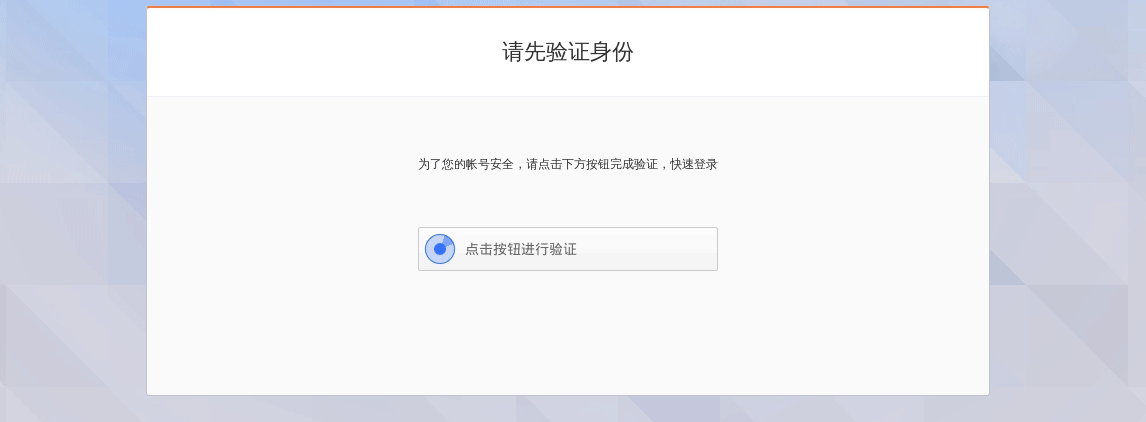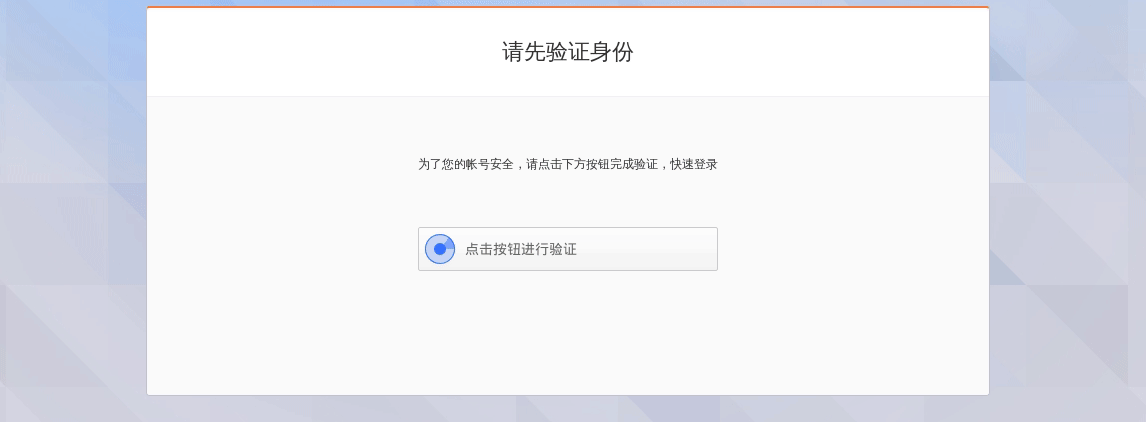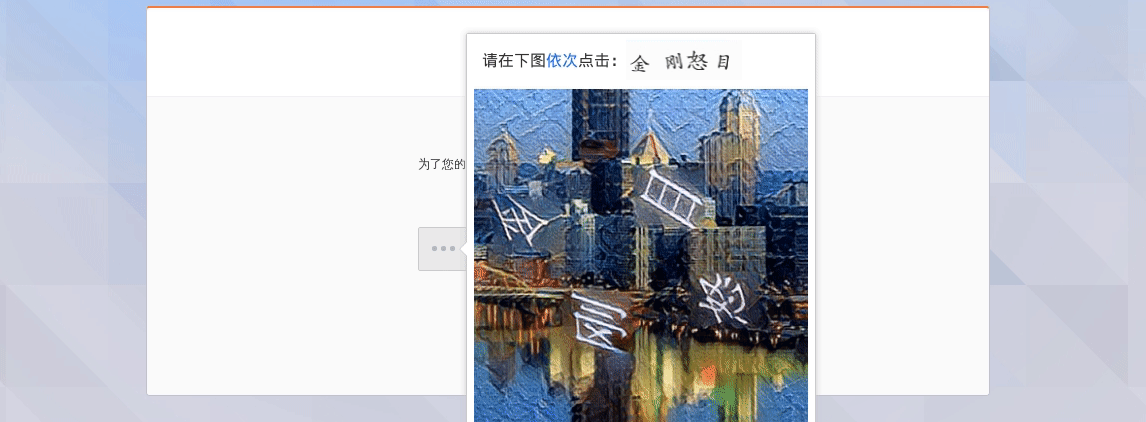
2.破解验证
其中PC站的数据和功能比较齐全,而m站和wap战登录比较简单,不需要验证码,一般只需极验的智能组合验证,代码通过几率比较大。所以本项目的基本原理是破解这个智能组合验证,登录成功后再调转到weibo.com。 智能组合验证
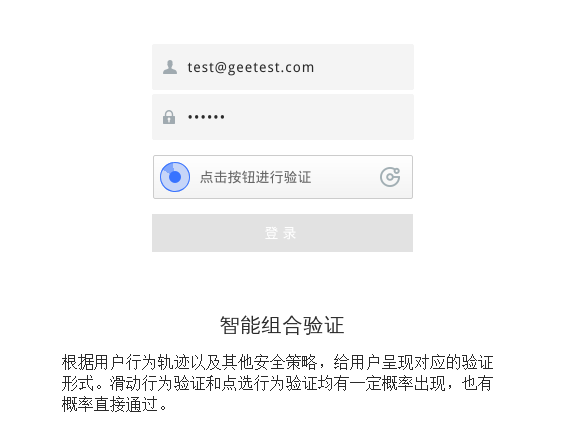
登录尝试了几次后发现直接写代码(webdriver 动作)点击验证往往会出错,观察到验证区域左侧的圆形部分的阴影扇形会跟着鼠标的位置而移动,于是模拟鼠标先进行移动,再进行点击后成功率提高,具体代码如下:
|
|
3.效果案例
效果如下: 不好意思,翻车了
注意: PC端微博登陆的安全规则,首先是无异常账号,在常用ip地址段登陆,前几次登陆基本不需要验证,如果错误了几次就需要验证,登陆后会返回重定向的地址,会被重定向两次才会登陆成功。因此运行本项目代码最好使用无验证的微博帐号。
完整代码位于:https://github.com/webscrapingproject/weiboRobot