[Python爬虫系列]1— 音乐平台外链以及歌词提取
20200624更新
之前准备网站背景音乐的时候,需要提供音乐的播放链接(同时也可以下载音乐)以及相关的歌曲信息,而主流的音乐平台一般并不提供外链,而网上的一些文章里提供的提取外链 方法大多 已经失效(尤其是qq音乐等安全性较高的平台)。本文章整合了四个主流音乐平台的音乐外链以及歌词的提取方法,并亲测可用。另外,非批量提取音乐外链可以使用一个非常万能的工具:https://music.liuzhijin.cn/
1. 网易云音乐外链提取
例子: https://music.163.com/#/song?id=1338695683
主要是利用三个api(从网上找来的):
- 歌曲mp3的api,需要歌曲的ID(即上面链接里的数字):
http://music.163.com/song/media/outer/url?id=1338695683.mp3 - 歌曲详细信息的api(从network里看的),结果以json格式呈现:
http://music.163.com/api/song/detail/?&ids=[1338695683]&csrf_token= - 获取歌曲的歌词等信息,结果也以json 格式呈现:
http://music.163.com/api/song/media?id=1338695683
主要代码如下:
|
|
2. 酷我音乐外链提取
例子:http://www.kuwo.cn/yinyue/359900
首先也是根据链接获取歌曲的ID,歌曲的外链也有一个现成的API: 从 http://player.kuwo.cn/webmusic/st/getNewMuiseByRid?rid=MUSIC_359900 这个链接可以获得歌曲的基本信息以及外链地址,以xml格式展现,使用pyquery选取需要的元素(mp3外链地址是path+resource/+mp3path)
<Song>
<music_id>359900</music_id>
<mv_rid>MV_0</mv_rid>
<name>恭喜发财</name>
<song_url>http://yinyue.kuwo.cnhttp://yinyue.kuwo.cn/yy/gequ-liudehua_gongxifacai/359900.htm</song_url>
<artist>刘德华</artist>
<artid>286</artid>
<singer>刘德华</singer>
<special>继续谈情 新曲·精选(豪华版)</special>
<ridmd591>708D8A7473AB20674441C4E73AEB982A</ridmd591>
<mp3size>7.73 MB</mp3size>
<artist_url>http://yinyue.kuwo.cnhttp://yinyue.kuwo.cn/yy/geshou-liudehua/%E5%88%98%E5%BE%B7%E5%8D%8E.htm</artist_url>
<auther_url>http://www.kuwo.cn/mingxing/%E5%88%98%E5%BE%B7%E5%8D%8E/</auther_url>
<playid>play?play=MQ==&num=MQ==&name0=uafPsreissY=&artist0=wfW1wruq&ssig10=NDIxNDYzODcw&ssig20=Mjc4NzQzNDkwMA==&musicrid0=TVVTSUNfMzU5OTAw&mvrid0=TVZfMA==&mp3size0=Ny43MyBNQg==&mrid0=TVAzXzM1OTkwMA==&msig10=MzY0NjI4OTAyNg==&msig20=NTQ2NzAzNjA3&mkvnsig10=ODI3NzU3MjI4&mkvnsig20=MjQ4MDU1NTU2MA==&mkvrid0=TVZfMjExNjIx&mvsig10=MA==&mvsig20=MA==&size0=My4xMiBNQg==&album0=vMzQ+My4x+kg0MLH+qGkvqvRoSi6wLuqsOYp&kalaok0=MA==&hasecho0=MQ==&filetype0=c29uZw==&score0=NQ==&source0=aHR0cDovL3d3dzMudnZ5YS5jb20vc29uZzIvVVVhdXRoL3pmYi8wMDU3Lzg1MzgwMDU0NS53bWE=&mvprovider0=&</playid>
<artist_pic>http://img2.kuwo.cn/star/starheads/120/5/c726edb09fd899d65e8e9e878436583_0.jpg</artist_pic>
<artist_pic240>http://img1.kuwo.cn/star/starheads/120/34/11/220267175.jpg</artist_pic240>
<path>m1/newmusic/2011/06/08/727429700.wma</path>
<mp3path>n2/2011/06/08/2318884138.mp3</mp3path>
<aacpath>a1/4/80/1838519701.aac</aacpath>
<wmadl>wmadl.cdn.kuwo.cn</wmadl>
<mp3dl>other.web.ra01.sycdn.kuwo.cn</mp3dl>
<aacdl>other.web.ra03.sycdn.kuwo.cn</aacdl>
<lyric>DBYAHlReXEpRUEAeCgxVEgAORRgLG0MXCRgaCwoRAB5UAwEaBAkEBhwaXxcAHVReSAsMAVEkOj0wJjpfXFZXSVU=</lyric>
<lyric_zz>DBYAHlReXEpRUEAeCgxVEgAORRgLG0MXCRgaCwoRAB5UAwEaBAkEBhwaXxcAHVReSAsMAVEkOj0wJjpfXFZXSVVDABsMFkRU</lyric_zz>
</Song>
歌词信息从初始url地址中提取,在初始的response中的javascript代码存在lrcList变量可以提取出来并加工成标准的lrc格式。
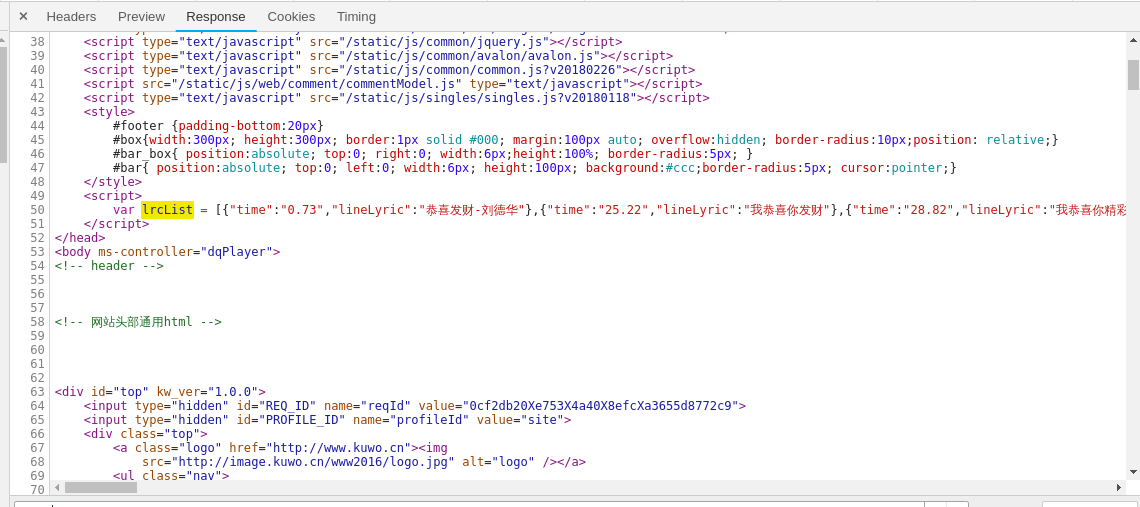
整体代码如下
|
|
3. 虾米音乐外链提取
例子:https://www.xiami.com/song/1792541433
虾米音乐也是主要利用了一个api:https://www.xiami.com/song/playlist/id/1792541433/object_name/default/object_id/0/cat/json,
要设置 headers头的User-Agent信息,部分返回的信息json格式如下:
{
"songId": "1792541433",
"songStringId": "xMPr7Lbbb28",
"songName": "\u5982\u679c\u6211\u4eec\u4e0d\u66fe\u76f8\u9047",
"subName": "\u7535\u89c6\u5267\u300a\u9752\u4e91\u5fd7\u300b\u63d2\u66f2 / What If...",
"newSubName": "\u7535\u89c6\u5267\u300a\u9752\u4e91\u5fd7\u300b\u63d2\u66f2",
"translation": "What If...",
"albumId": 2100337262,
"albumStringId": "nmTM4c70144",
"artistId": 3110,
"singers": "\u4e94\u6708\u5929",
"mvId": 492453,
"cdSerial": 1,
"track": 1,
"pinyin": "ru guo wo men bu ceng xiang yu",
"price": "2.00",
"albumPrice": "0.00",
"bakSongId": 0,
"panFlag": 0,
"musicType": "NORMAL",
"bakSong": null,
"lyricInfo": {
"lyricId": 14012004,
"lyricType": 3,
"lyricFile": "//img.xiami.net/lyric/33/1792541433_1524734731_7325.trc",
"isOfficial": true,
"userId": 0,
"userName": null,
"gmtModified": 1524734731000
},
"pic": "//img.xiami.net/images/album/img10/3110/21003372621469680510_1.jpg",
"album_pic": "//img.xiami.net/images/album/img10/3110/21003372621469680510.jpg",
"rec_note": ""
}
歌词的lrc文件地址也可以从上面的response得到。特殊的是歌曲外链的地址是经过凯撒方阵加密的,此处借用github上的代码来解密(https://github.com/Flowerowl/xiami/blob/master/xiami.py)
整体代码如下:
|
|
4. qq音乐外链提取
qq音乐比较复杂一点,想要提取音乐的外链,必须要先获得一个有时效的vkey,再凭借vkey得到音乐链接(因此该链接并非永久链接)
-
从原始链接获得演唱者等基本信息(javascript里的g_SongData),还可以获得歌曲的songmid,strMediaMid等信息来获取vkey
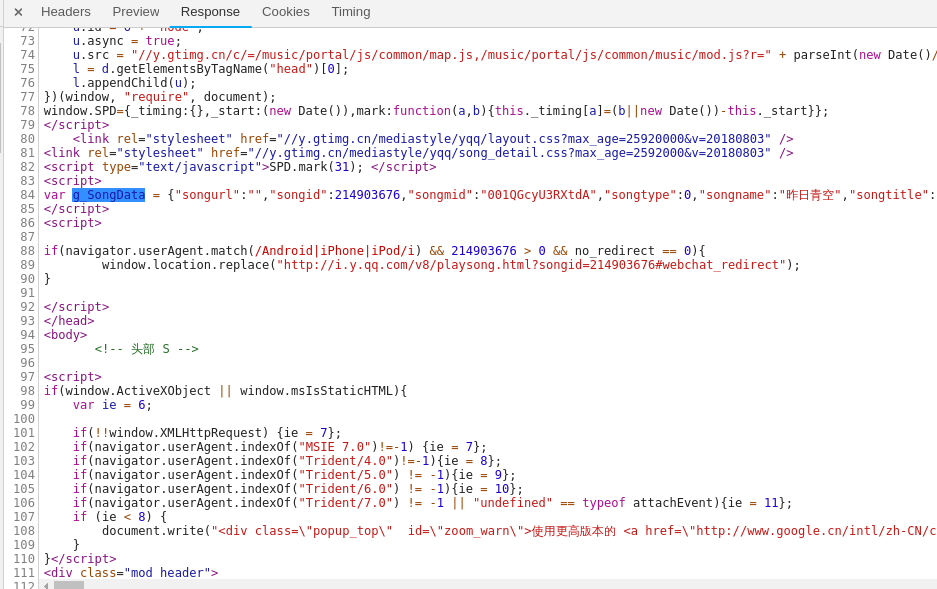
-
构建以下url来获取歌曲的vkey
https://u.y.qq.com/cgi-bin/musicu.fcg?data={"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":
{“guid”:“0”,“songmid”:["’ +songData[‘songmid’] + ‘"],“uin”:“0”}}} -
歌词的请求url 是: https://c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric_new.fcg
, 需要包装好headers,参考network里的headers以及params
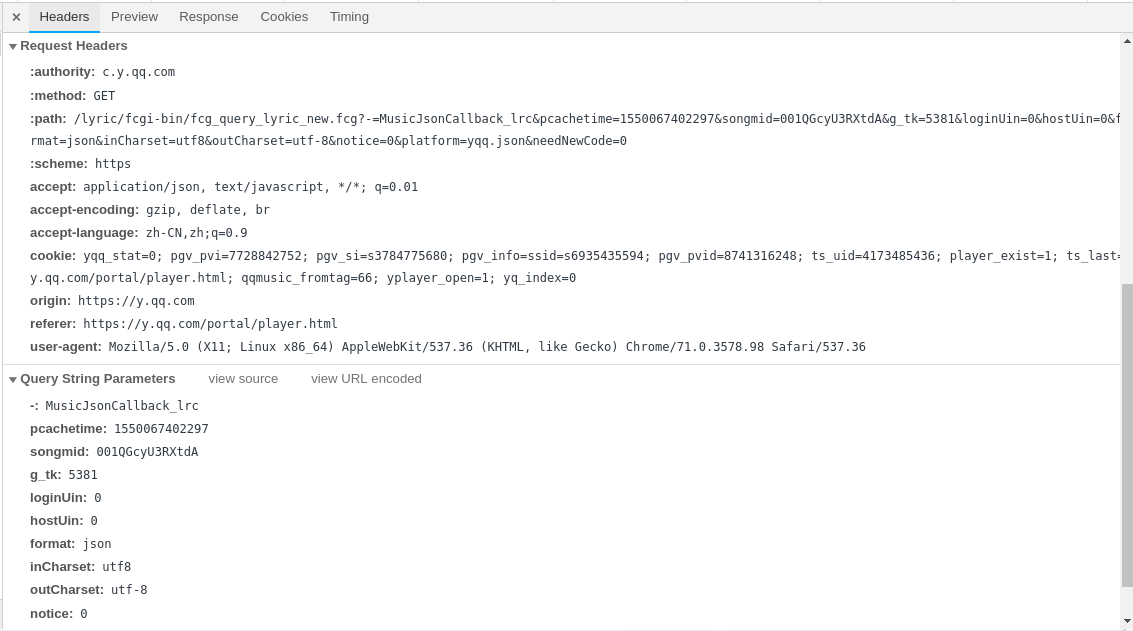
整体代码如下:
|
|
本项目的完整代码位于:https://github.com/webscrapingproject/musicExtracter
参考
- 网易云音乐mp3外链、真实地址下载方法 http://www.cnblogs.com/MirageFox/p/7995929.html
- 网易云音乐下载接口加密破解思路及步骤(附 Python 源码) http://itindex.net/detail/59279-%E7%BD%91%E6%98%93-%E9%9F%B3%E4%B9%90%E4%B8%8B%E8%BD%BD-%E6%8E%A5%E5%8F%A3
- 提取【酷我音乐MP3】外链url完整地址–可用于做背景音乐 https://blog.csdn.net/novofly/article/details/50823570
- 解密虾米data-mp3(凯撒阵列加密) https://www.jianshu.com/p/3411b0e48581
- 虾米音乐链接crack(Python版)http://lazynight.me/3391.html
- 获取qq音乐外链方法+源码 https://blog.csdn.net/csdn_lqr/article/details/51594729
- python爬虫之QQ音乐全站歌曲爬取 https://www.pythonf.cn/read/29575
- Web端虾米音乐爬虫实战分析 处理参数JS加密 https://www.e1yu.com/9431.html
- 使用Python抓取Web端QQ音乐排行榜 批量下载QQ音乐到本地 https://www.e1yu.com/6120.html